MoSh: Motion and Shape Capture in the Age of AI
Test-of-Time Award Winner, SIGGRAPH Asia 2024
03 December 2024 9 minute read

"MoSh: Motion and Shape Capture from Sparse Markers," by Matthew Loper, Naureen Mahmood, and Michael J. Black, has won the 2024 ACM SIGGRAPH Asia Test-of-Time Award.
What is MoSh? Why is it still relevant after 10 years? What does it have to with Generative AI? And, what is the future of "motion capture"?
Motion capture, or mocap, is broken and has been for a long time.
The use of cameras to capture and analyze human movement dates back to the work of Muybridge at the dawn of photography. Today the "gold standard" approach is based on using reflective markers attached to the body and a set of calibrated cameras around the subject that detect the makers and compute their 3D coordinates. Given the 3D marker locations, one then "solves" for the 3D skeleton that plausibly gave rise to the markers. The motion of this skeleton can then be retargeted to new graphics characters, analyzed to detect disease, or used to evaluate athletic performance.
The technology has been around for 40 years and mocap labs are common. Commercial systems can estimate the 3D locations of the markers with sub-millimeter precision. So why do I say mocap is broken? Why do animators love to hate it?
Look no further than The Polar Express.

This was the first movie animated completely with motion capture and nobody liked the result. The performances looked "wooden" and lacked all the nuance of live humans. Something essential about human behavior was lost in the translation from 3D markers to 3D humans.
Given "sub-millimeter" accuracy, what went wrong?
Humans are not skeletons
The core problem is that mocap tries to estimate our skeleton but we're not skeletons. Humans are fleshy, squishy, flexible creatures and we express ourselves using the surface of our body. We interact with the world through our skin and not our bones. The body surface is what we want to capture if we want to maintain the nuance of human behavior.
Traditional mocap markers are place on the surface of the body and markers contain the signatures of human behavior. The problem is that the traditional approach infers a skeleton and throws away the surface information the markers contained. All the jiggly nuance, flexing muscles, and deforming skin is treated as "noise" -- it's a nuisance. In fact, one tries to put the markers on bony places where they are likely to jiggle the least. This is exactly wrong. If you want to capture what it means to be human, you want markers on the body in places that capture all that expressive soft-tissue movement.
On the left is a real body moving and on the right is a 3D capture that throws away all the soft tissue motion:

Note that our skeleton is never directly observed and the estimated skeleton is not an actual human skeleton -- it's a graphics approximation.
So, the traditional process is this: track markers on the surface of the body, try to ignore the movement of the makers caused by soft-tissue, solve for an approximate skeleton, throw away the markers, then retarget the skeleton onto your character.
It should not be surprising that the result doesn't look human.
The MoSh approach
MoSh turns the problem on its head. The 3D markers are the important thing and they carry all the information we have about the body. Rather than fit a skeleton to the makers, we fit a body. That is, we estimate the body surface from the markers such that this surface retains the original nuance.
The problem is that there are typically 40-60 makers on the body, which is very sparse. How can we get the full body surface from only a handful of 3D points?
The key idea was to leverage a parametric 3D human body model where the parameters of the model control its 3D shape and pose. At the time of publication, we used a model called BlendSCAPE but later upgraded this to use the SMPL body model. The key idea is that, if you knew the marker locations on the 3D body model, then you could solve for the shape and pose parameters that align the 3D model with the observed 3D marker locations.
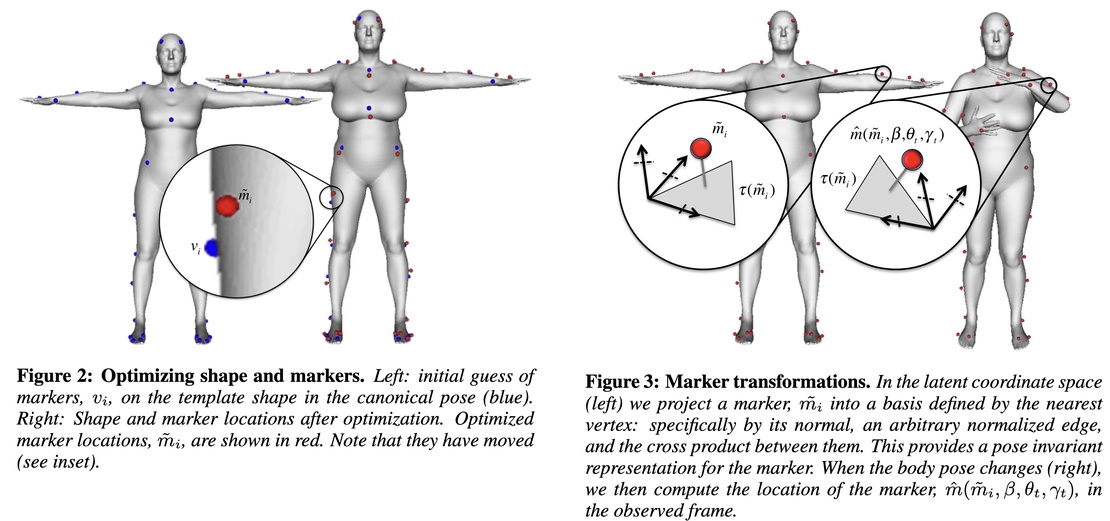
The technical challenge is that the exact marker locations on the body model are not known. You only know them approximately. Consequently, the first step of MoSh is to solve for the precise location of the markers on the body surface. This includes their location on the surface as well as their distance from the surface. Given 12 randomly chosen mocap frames, we fit a single body shape and the locations of the markers. Once these are known, we assume that they don't change throughout the capture session.
Given a sequence of 3D markers as input we fit the sequence of poses (we assume the body shape is constant). The SMPL body model has a skeleton inside it so inferring the surface of the body actually also computes the skeleton. Thus, nothing is lost compared to traditional mocap.
Everybody jiggles
The markers actually move around relative to the skeleton. A key insight of MoSh is that this relative motion is not noise -- it captures our soft tissue moving. In the original MoSh paper and a follow-on, we show that we can model human soft tissue motion in a low-dimensional space and actually solve for the "jiggle" from the markers.
Once we can do that, we no longer have to put markers just on "bony" regions of the body. In fact, putting markers on the softer parts of the body give us more information and the resulting body motions are more natural. In the video, the green balls are the actual markers on the subject while the red balls are the locations of the markers on the 3D body model. If the body shape is assumed to be fixed (i.e. no jiggle), then there can be big differences between the markers -- this is what is traditionally seen as noise. On the right, the body shape is adjusting over time (see the inset) and now the red markers better track the green ones. We've effectively captured the body shape, the motion of the limbs, and the soft tissue movement.

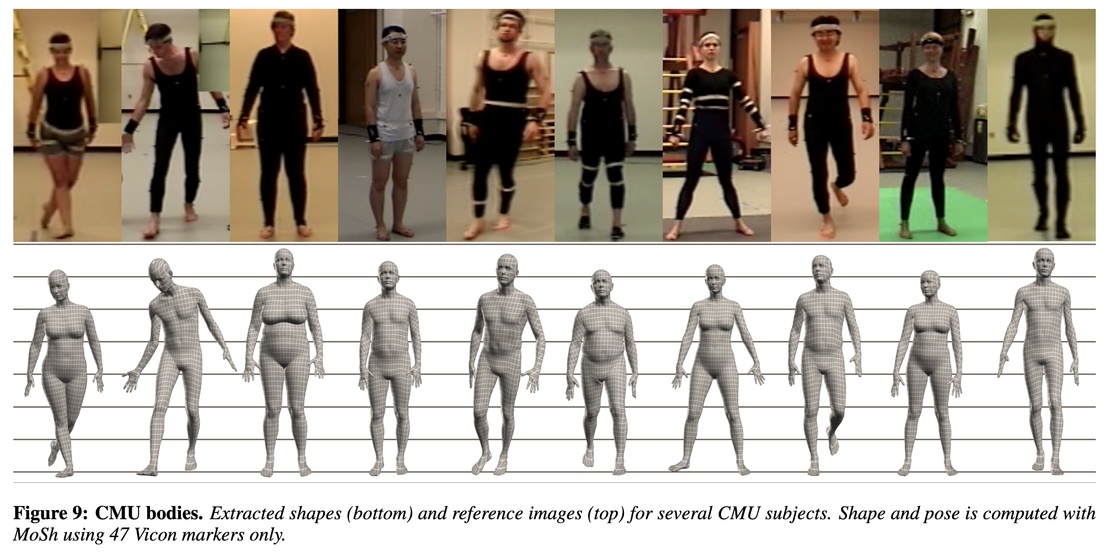
Note that the markers contain enough information that it is possible to estimate a person's body shape relatively accurately from just a few makers. This means that, even with the standard marker set of 47 markers, we can turn a mocap system into an approximate "body scanner" (see Fig. 9).
Standing the "test of time"
So why has MoSh stood the test of time award? Why is it still relevant 10 years after publication? First, MoSh produces really natural animations that are hard to replicate with standard automated methods. It just works. To get this level of detail from skeletal motion capture requires significant animator expertise and time.

Second, MoSh is a workhorse that we've used for many projects. Most importantly we used it to create the AMASS dataset. AMASS is the largest collection of human motion capture that is in a consistent format (SMPL-X). This where Generative AI comes in. AMASS is the first dataset big enough to train neural networks to generate human motions. Before AMASS, every mocap dataset used a different skeleton. This made it hard to combine different datasets for training meaning that there was not enough data to train neural networks to model human movement. We took all available datasets that included markers and MoShed them, producing a consistent database with over 45 hours of data. This number is still growing and is somewhere around 90 hours now.
We also used MoSh to create the GRAB and ARCTIC datasets, which involve humans interacting with objects. For this, we extended the original method to also capture the movement of the fingers and to track the objects and the body together.

What's the future of mocap and MoSh?
MoSh taught us that motion capture should not be just about skeletons -- it's about capturing the whole body in motion with all its complexity. What is surprising and exciting was that full-body capture is possible from a small set of mocap markers.
There are two key developments going forward.
1. Real skeletons: For applications in biomechanics, sports analytics, gait analysis, etc., we need to know skeletal motion. Rather than use a graphics-inspired skeleton, we want a real, biomechanically-correct, skeleton and we want to know precisely how it's moving. To that end, we took 3D humans from the AMASS dataset and fit a biomechanical skeleton inside. This gives paired training data of 3D humans together with their skeleton. This enabled us to develop SKEL, which infers the true skeleton inside the body from the outside surface.

2. Every pixel is a marker: If 40-60 markers are good, maybe thousands are even better. Given an image, can we treat every pixel as a marker and infer body shape and motion from video? We've made huge progress in this direction and eventually markerless capture from video will replace marker-based systems in most scenarios. That will take mocap out of the studio and into the world and will open up the study of human movement in natural settings.
Commercial methods like Meshcapade's Mocapade product can now recover 3D human pose and shape accurately from video, even with very complex motions:

Putting these together is the key to performing biomechanics in the wild. The result below uses WHAM to estimate the 3D body from video in world coordinates and uses SKEL to put infer the skeleton (thanks to Soyong Shin).

Resources
Project page includes links to download data.
Watch the MoSh video.
Read the original SIGGRAPH Asia paper.
Citation:
MoSh: Motion and Shape Capture from Sparse Markers, Loper, M.M., Mahmood, N., Black, M.J., ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 33(6):220:1-220:13, ACM, New York, NY, USA, November 2014.
If you have mocap marker data and want to contribute to the AMASS dataset we can MoSh it for you. Please email amass@tue.mpg.de
If you want to try using MoSh yourself, we updated the original MoSh to output SMPL-X (MoSh++) and there is code for this on GitHub.
If you have commercial data that you want processed with MoSh, please reach out to Meshcapade at sales@meshcapade.com
To try Meshcapade's markerless shape and motion capture, visit https://me.meshcapade.com/
For work on inferring the human skeleton from the outside of the body, see SKEL.



The Perceiving Systems Department is a leading Computer Vision group in Germany.
We are part of the Max Planck Institute for Intelligent Systems in Tübingen — the heart of Cyber Valley.
We use Machine Learning to train computers to recover human behavior in fine detail, including face and hand movement. We also recover the 3D structure of the world, its motion, and the objects in it to understand how humans interact with 3D scenes.
By capturing human motion, and modeling behavior, we contibute realistic avatars to Computer Graphics.
To have an impact beyond academia we develop applications in medicine and psychology, spin off companies, and license technology. We make most of our code and data available to the research community.