Third wave 3D human pose and shape estimation
Beyond 3D to understanding humans
04 December 2023 7 minute read
We recently released a pre-print describing PoseGPT, a multi-modal large language model (LLM) that is trained to estimate 3D human pose from images, text, or both. This is interesting because it shows that an LLM can estimate 3D humans from images but this may not be so surprising. After all, LLMs are large capacity models and can be fine-tuned to do many tasks. More interesting and important, is that PoseGPT learns to relate 3D human pose to more general concepts about humans.
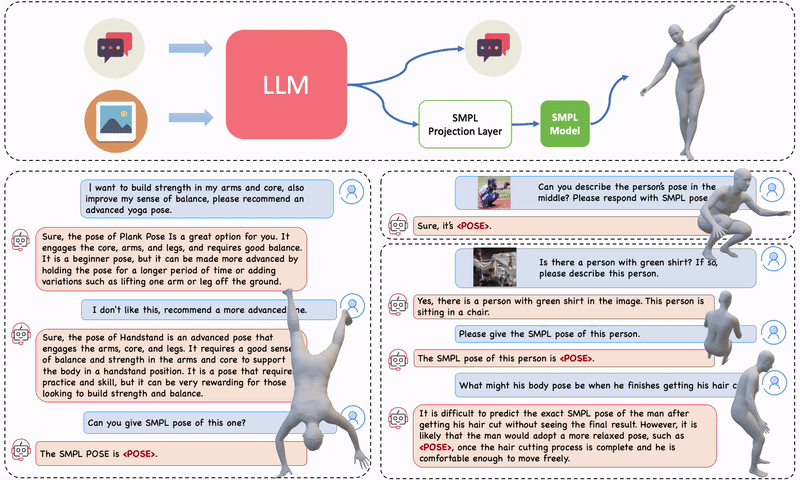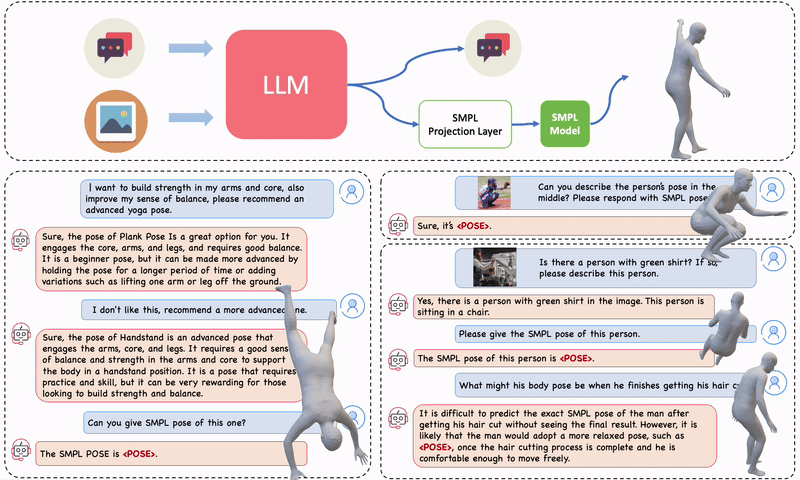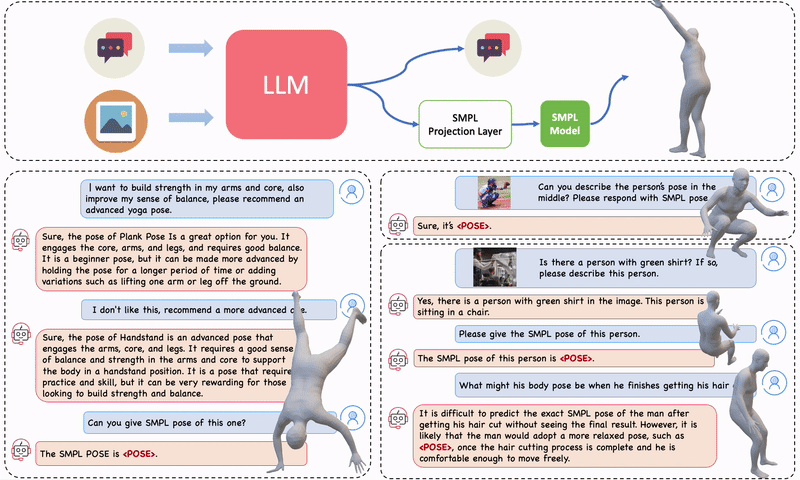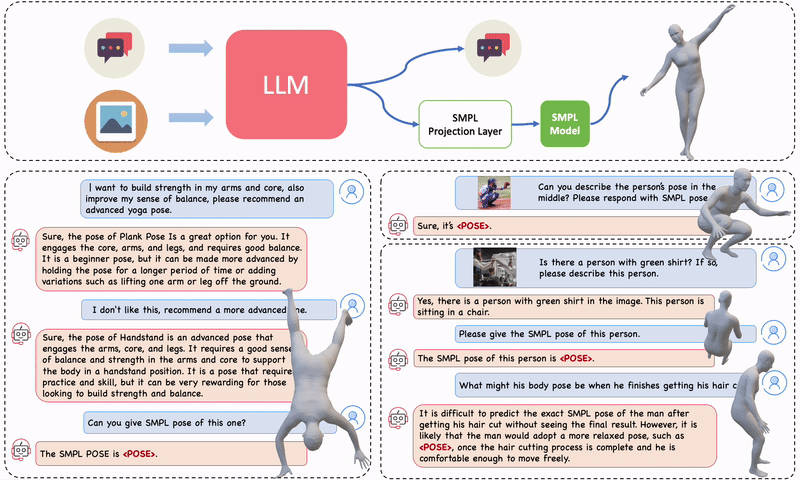
Figure 1. PoseGPT is a multi-model LLM designed for chatting about human pose that produces 3D human poses (SMPL pose parameters) upon user request. PoseGPT features a specialized SMPL projection layer trained to convert language embeddings into continuous-valued 3D human pose parameters. You can chat with PoseGPT both without (left) and with (right) an image input. Upon detection of a pose token, the token is used to estimate the SMPL pose parameters and subsequently generate the corresponding 3D body mesh.
For example, you can ask it for the 3D pose of a man proposing marriage to a woman. You can ask it to demonstrate yoga poses. Or you can show it an image of someone and ask how their pose would be different if they were tired. These examples demonstrate that PoseGPT is able to combine its general knowledge of humans and the world with its new knowledge about 3D human pose.
I see this as a fundamental paradigm shift in the field -- the "third wave" of 3D human pose and shape estimation. To understand why this third wave is important, it's worth reviewing the first two waves.
The first wave: Optimization
The goal is to take an image or video and estimate the parameters of a 3D human model like SMPL. The output is a 3D mesh that has the pose and shape of the person in the image or video.
The first fully automatic method for this was SMPLify [1]. SMPLify uses 2D keypoints that are detected by another method and it minimizes an error function to fit the SMPL parameters to the keypoints. Specifically, it projects SMPL’s 3D joints into the 2D image and minimizes the distance between the detected and projected keypoints. There are many valid solutions to this problem so it takes into account “prior” information about body shape and pose.
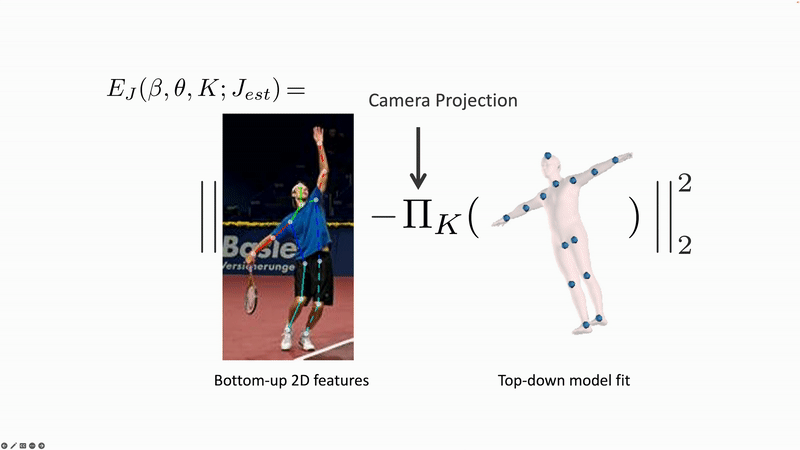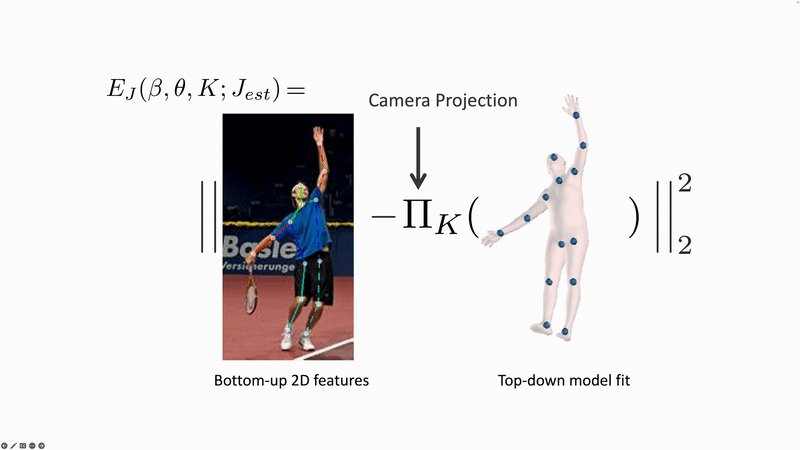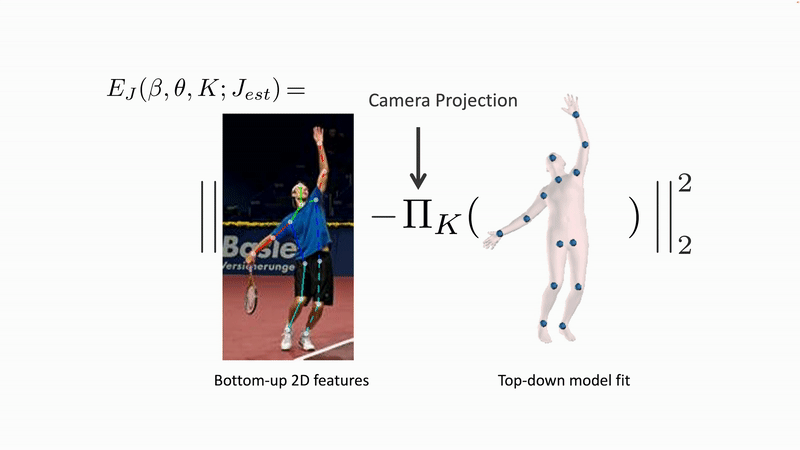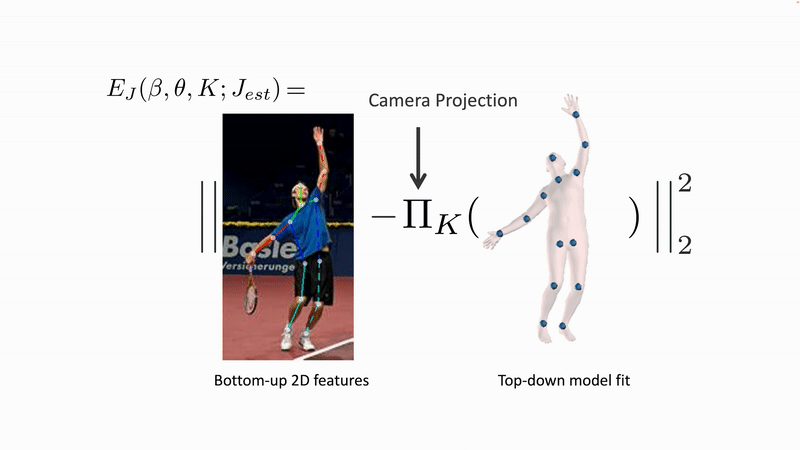
Figure 2. SMPLify solve an optimization problem that estimates the 3D pose and shape parameters of SMPL such that the 3D joints (blue dots) match detected 2D joints when they are projected into the image. This problem is underconstrained so SMPLify uses "priors" that make sure the body shape and pose are likely.
SMPLify is still widely used because it can produce very accurate results. In fact, some version of SMPLify is used to generate most pseudo ground-truth data from images. It is also super flexible and can easily be extended to multiple views, video, or to use new features. This does not require retraining a network.
The disadvantages, however, are that it’s slow and you have to define many things by hand.
Second wave: Regression
The second wave started with HMR (Human Mesh Recovery), which introduced the first deep neural network that could directly regress SMPL parameters from an image. The method uses image features computed using a pre-trained backbone (e.g. Resnet pre-trained on ImageNet classification). It then uses a rather simple MLP to regress from these features to SMPL parameters. To make this work, HMR introduced an iterative regression framework and a discriminative training approach.
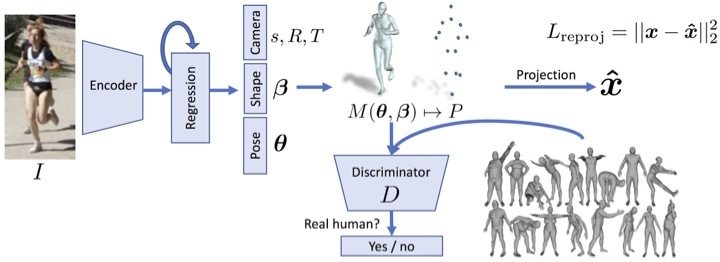
Figure 3. HMR takes a cropped image region around a person, embeds it in an image feature space and then regreses SMPL pose and shape parameters from the image features. The loss is on 2D keypoints, just like in SMPLify. And, like with SMPLify, the problem is underconstrained. Rather than add explicit priors like SMPLify, HMR trains a discriminator to detect real vs generated 3D humans. The discriminator effectively forces the network to learn the "prior" over valid human shapes and poses.
With improvements in the image backbones and their pretraining, as well as better 3D training data, current methods do not need either the iterative regression or the discriminative training. The core idea of HMR, however, remains in many state-of-the-art methods.
This second wave has driven the popularity and applications of 3D human pose estimation because it is fast and robust (it not as accurate as optimization). One also doesn’t need to hand-define all the terms used in the first wave. Just train the network on enough good data and it will learn the priors inherent in the data.
The field has been progressing nicely in this second wave, with ever improving accuracy and robustness.
Third wave: Reasoning
PoseGPT represents a departure from the first two waves in terms of methodology and scope. First, let’s consider the methodology. Instead of a specialized backbone, PoseGPT leverages a large, pre-trained, multi-modal LLM. We fine-tune this using a variety of tasks that involve language queries that require the LLM to produce 3D poses or descriptions of poses. The nature of the training data and process is philosophically quite different from the second wave. Additionally, second-wave methods rely on lots of data augmentation to be robust. But LLMs already know so much about the visual world that they can be robust to things like occlusion without data augmentation.
Second, while the methodology and training are different, this is not the key thing that defines the third wave. The key difference is that the first two phases are fundamentally about “metric reconstruction”. They estimate a 3D mesh but do not tell us anything about what this mesh might mean – i.e., they don’t tell us what the person is doing or why.
By building 3D PoseGPT on top of an LLM we move from estimation to understanding. Human pose is now embedded in the world knowledge of the LLM and it can reason about this pose and discuss it with us. This opens up research on Human Behavior Understanding (HBU) that goes beyond traditional action recognition by focusing on contextualized human activity.
Which brings me to my third point. I think there is something even more important here that we have not yet fully explored or exploited. By relating 3D pose, images, and language, we open up the possibility of training our models at scale using wildly diverse data that grounds human pose in the context of the world, social interactions, contact with objects, emotions, and so on. Our estimates of human motion can now be situated and so can our training.
The PoseGPT paper offers an early experiment in this HBU direction. In contrast to second-wave methods, which typically only look at a small cropped region of an image, PoseGPT looks at the whole image and can reason about people in context. You can ask it about “the man sitting on the bench” or “the girl riding the bike”. This changes everything because we can now relate human pose to the scene and to human action in the world. This will lead us to train methods that simultaneously estimate human pose (and motion) and understand it. And it will let us leverage language to improve human pose estimation.
Summary
I've focused here on methods that compute the 3D shape and pose of a human from images or video. There is a long line of work that pre-dates this that focuses on estimating only the 2D or 3D joints of an articulated skeleton. There is also a huge literature on human action recognition from pixels. This blog only addresses methods that compute a full 3D body mesh.
In this area, one can think of the first wave as being about accuracy, the second about speed and robustness, and the third about reasoning. We are just at the beginning of the third wave but the possibilities are exciting. I’ve long argued that for computers to be full partners with humans, they will need to understand us – our movements, our emotions, our actions, and our intentions. The third wave would not have begun without the first two waves and will leverage them heavily going forward. But it now offers us a path towards computers that see and understand humans.
References
[1] SMPLify: Bogo, F., Kanazawa, A., Lassner, C., Gehler, P., Romero, J., Black, M. J., Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image, ECCV 2016.
[2] Angjoo Kanazawa, Michael J. Black, David W. Jacobs, Jitendra Malik. End-to-end Recovery of Human Shape and Pose, CVPR 2018.
[3] Yao Feng, Jing Lin, Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, Michael J. Black, PoseGPT: Chatting about 3D Human Pose. arXiv:2311.18836 [cs.CV], 2023.
The Perceiving Systems Department is a leading Computer Vision group in Germany.
We are part of the Max Planck Institute for Intelligent Systems in Tübingen — the heart of Cyber Valley.
We use Machine Learning to train computers to recover human behavior in fine detail, including face and hand movement. We also recover the 3D structure of the world, its motion, and the objects in it to understand how humans interact with 3D scenes.
By capturing human motion, and modeling behavior, we contibute realistic avatars to Computer Graphics.
To have an impact beyond academia we develop applications in medicine and psychology, spin off companies, and license technology. We make most of our code and data available to the research community.