Creating digital humans: Capture, Modeling, and Synthesis
ICCV 2021 papers in context
18 October 2021 Michael J. Black 16 minute read


Some of the ICCV 2021 authors
In Perceiving Systems, together with our external collaborators, we are creating realistic 3D humans that can behave like real humans in virtual worlds. This work has many practical applications today and will be critical for the future of the Metaverse. But, in Perceiving Systems, our goal is a scientific one -- to understand human behavior by recreating it.
“What I cannot create, I do not understand.” Richard Feynman
Our ability to perceive an act in novel environments is critical for our survival. If we can recreate this ability in virtual humans, we will have a testable model of ourselves.
Our approach has three interrelated pillars: Capture, Modeling and Synthesis. Our approach starts by capturing humans, their appearance, their movement, and their goals. Using this captured data, we model how people look and how they move. Finally, we synthesize humans in 3D scenes in motion and assess how realistic they are.
Our ICCV 2021 papers provide a nice snapshot of this approach and the current state of the art. I'll try to put them in context below.
Capture
To learn about humans we need to capture both their shape and their movement. In capture there is always a tradeoff between the quality and quantity of the data. In the lab we can capture precise, high-quality, data but the amount is always limited. So we also capture in-the-wild and we are constantly developing new methods to estimate human pose and shape (HPS) from images and video. At ICCV, we have papers using both approaches.
In the lab:
SOMA: Solving Optical Marker-Based MoCap Automatically
Ghorbani, N., Black, M. J.
https://soma.is.tue.mpg.de/
The "gold standard" for capturing human movement is marker-based motion capture (mocap). To be useful, the mocap process transforms a raw, sparse, 3D point cloud into usable data. The first step is to clean and "label" the data by assigning 3D points to specific marker locations on the human body. After labeling, one can then "solve" for the body that gave rise to the motions. A key barrier to capturing lots of mocap data is the labeling process, which, even with the best commercial solutions, still requires manual intervention. Occluded markers and noise cause problems, in particular when one uses novel marker sets or humans interact with objects.
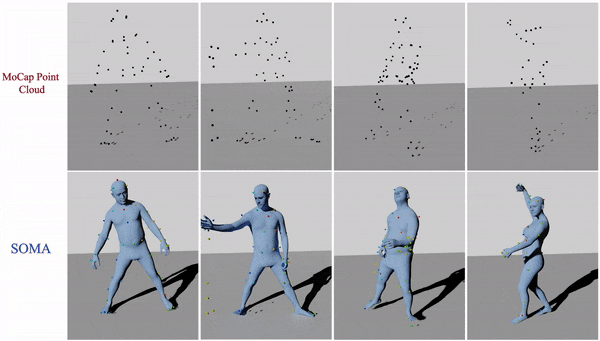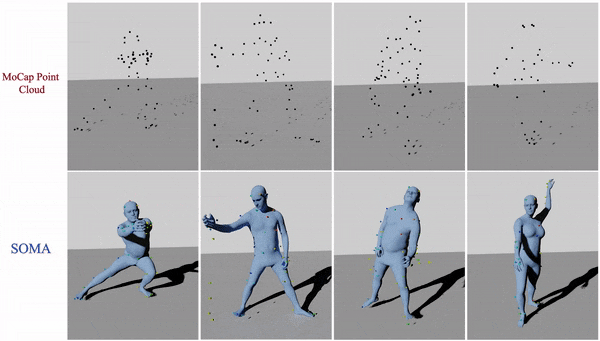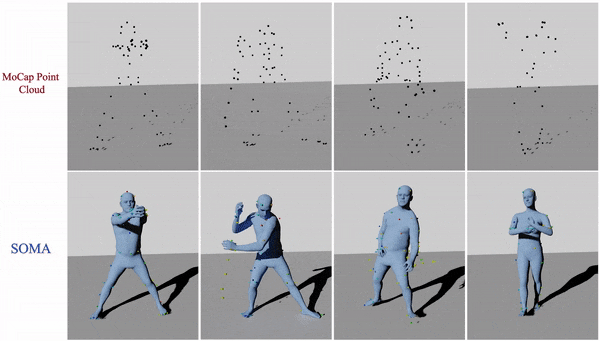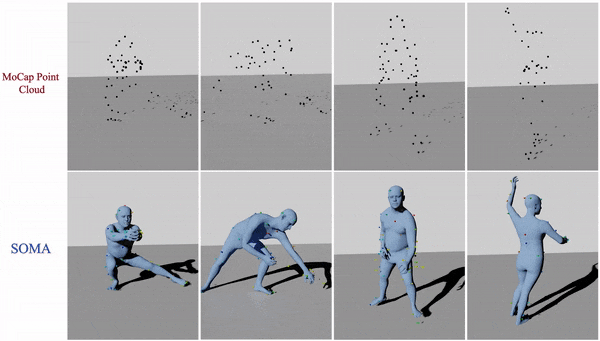
At ICCV we address this with SOMA, which takes a raw point cloud and labels it automatically using a stacked attention mechanism based on transformers. The approach can be trained purely on synthetic data and then applied to real mocap point clouds with varying numbers of points.
Using SOMA, we are able to automatically fit SMPL-X bodies to raw mocap data that has never before been processed because it was too time consuming. We've added some of this data to the AMASS dataset.
Topologically Consistent Multi-View Face Inference Using Volumetric Sampling
Li, T., Liu, S., Bolkart, T., Liu, J., Li, H., Zhao, Y.
https://tianyeli.github.io/tofu
Similarly, facial capture data is critical for building realistic models of humans. Unlike mocap, people typically capture dense 3D face geometry. To be useful, e.g. for machine learning, the raw 3D face scans need to be brought into alignment with a template mesh in a process known as registration. Registration using traditional methods can be slow and imperfect.

In ToFu (Topologically consistent Face from multi-view), the authors describe a framework to infer 3D geometry that produces topologically consistent meshes using a volumetric representation. This is unlike prior work that is based on a 3D "morphable model". ToFu employs a novel progressive mesh generation network that embeds "the topological structure of the face in a feature volume, sampled from geometry-aware local features." ToFu uses a coarse-to-fine approach to get details and also "captures displacement maps for pore-level geometric details".
In the wild:
PARE: Part Attention Regressor for 3D Human Body Estimation
Kocabas, M., Huang, C. P., Hilliges, O., Black, M. J.
https://pare.is.tue.mpg.de/
To capture more complex and realistic behaviors than is possible in the lab, we need to track 3D human behavior in 2D video. There has been rapid progress on human pose and shape estimation but existing HPS methods are still brittle, particularly when there is occlusion. In PARE, we present a novel visualization technique that shows how sensitive existing methods are to occlusion. Using this, we find that small occlusions can have long-range effects on body pose.

To address this problem, we devise a new attention mechanism that learns where to look in the image to gain evidence about the pose of occluded parts. We train the approach in the intial stages using part segmentation maps. This helps the network learn where to attend. But when a part is occluded, the network needs to look elsewhere so we remove this guidance as training progresses. The resulting method is significantly more robust to occlusion than recent baseline methods.
SPEC: Seeing People in the Wild with an Estimated Camera
Kocabas, M., Huang, C. P., Tesch, J., Müller, L., Hilliges, O., Black, M. J.
https://spec.is.tue.mpg.de/
Robustness to occlusion is not the only thing limiting the accuracy of HPS methods. Current approaches typically assume a weak perspective camera model and estimate the 3D body in the camera coordinate system. This causes many problems, particularly when there is significant foreshortening in the image, which is very common in images of people. To address this we train SPEC, which uses a perspective camera and estimates people in world coordinates.

Our first step was to create a dataset of rendered images with ground truth camera parameters which we use to train a network called CamCalib that regresses camera field of view, pitch, and roll from a single image. We then train a novel network for HPS regression that concatenates the camera parameters with image features and uses these together to regress body shape and pose. This results in improved accuracy on datasets like 3DPW. We also introduce two new datasets with ground truth poses and challenging camera views. SPEC-MTP uses the "mimic the pose" idea from the CVPR'21 TUCH paper to capture real people but extends the idea to also capture camera calibration. SPEC-SYN uses the rendering method from the AGORA dataset but with more challenging camera poses that induce foreshortening.
Learning To Regress Bodies From Images Using Differentiable Semantic Rendering
Dwivedi, S. K., Athanasiou, N., Kocabas, M., Black, M. J.
https://dsr.is.tue.mpg.de/
When training HPS regressors like PARE and SPEC, we typically rely on 2D image keypoints and sometimes 3D keypoints or HPS parameters. There's a lot more information in the image, however, that is not being exploited. For example, current 3D HPS models are "minimally clothed", yet people in real images typically wear clothing. Here we show that knowing about clothing in the image can help us train neural regressors that better estimate HPS.
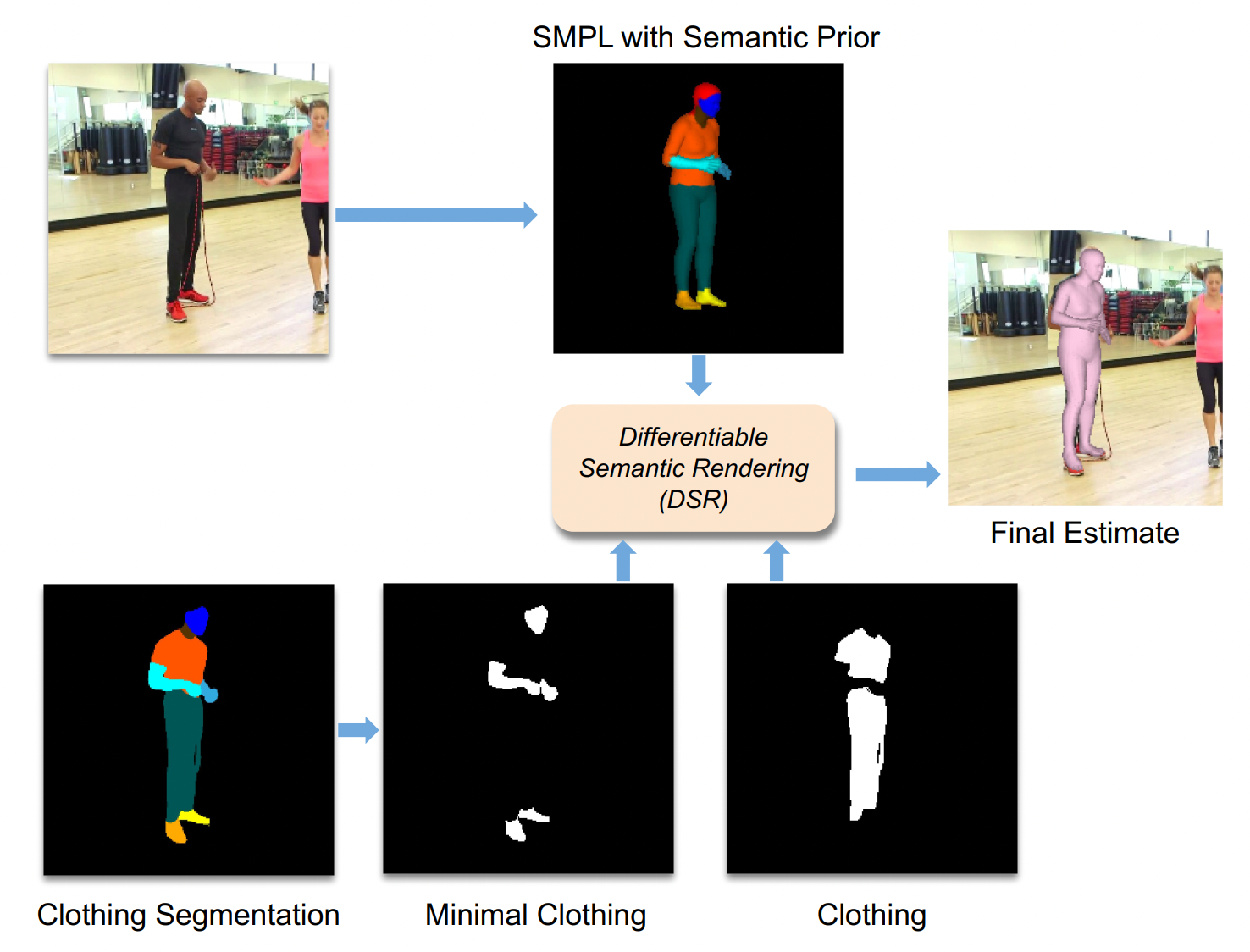
The key idea is to leverage information about clothing during training. For example, in areas of the body that show skin, we expect the the body to fit tightly to the image silhouette. In areas where there is clothing, however, we expect the body to fit inside the clothing region.
We use Graphonomy to segment the input images into clothing regions, but how do we relate the body to clothing? For this, we leverage the AGORA dataset again. Specifically, we compute the semantic clothing segmentation for all the 3D clothed bodies in AGORA and project this onto the 3D mesh of the ground truth SMPL-X bodies. From this, we learn a simple per-vertex prior that captures how likely each vertex is to be labeled with each clothing label. We then define novel losses that exploit this prior for the clothed and un-clothed regions. When trained with clothing information, the resulting model is more accurate than the baselines and we find that it better positions the body inside the clothing.
Monocular, One-Stage, Regression of Multiple 3D People
Sun, Y., Bao, Q., Liu, W., Fu, Y., Black, M. J., Mei, T.
https://ps.is.mpg.de/publications/romp-iccv-2021
Each of the above papers addresses an important problem in human capture from RGB but each of these methods assumes that the person has been detected and cropped from the image. This cropped image is then fed to a neural network, which regresses the pose and shape parameters. SPEC takes a step towards using the whole image since it estimates camera parameters using the full image and exploits these in estimating the pose of the person in the crop. But, we argue that there is much more information in the full image and that this two-stage process (detect then regress) is slow and brittle. This is particularly true when there is significant person-person occlusion in the image. In such cases, a tight bounding box may contain multiple people without sufficient context to differentiate them. In ROMP, we argue, instead, for a one-stage method that processes the whole image, can exploit the full image context, and is efficient when estimating many people simultaneously.
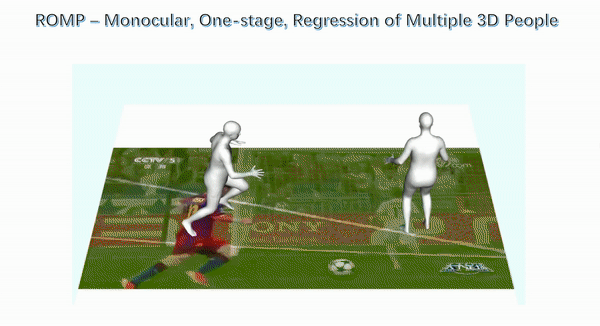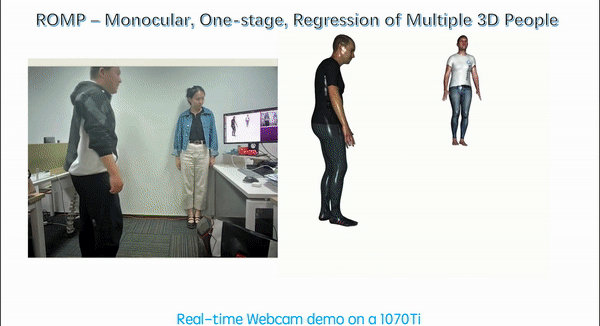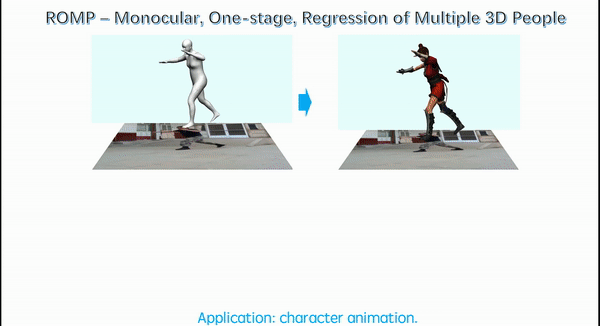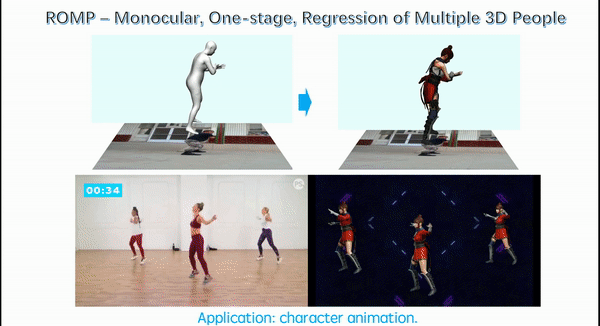
Instead of detecting bounding boxes, ROMP uses a pixel-level representation and simultaneously estimates a Body Center heatmap and a Mesh Parameter map. The Body Center heatmap captures the likelihood that a body is centered at a particular pixel. We employ a novel repulsion term to deal with bodies that are highly overlapping. The Parameter map is also a pixel-level map that includes camera and SMPL model parameters. We then sample from the Body Center heatmap and obtain the parameters of the 3D body from the location in the Parameter map. ROMP runs in realtime and estimates the pose and shape of multiple people simultaneously. We think that this is the future -- why focus on cropped people? We want to estimate everyone in the scene and allow the network to exploit all the image cues in this process.
Modeling
Capturing data is only the first step in building virtual humans. Modeling takes data that we've captured and turns it into a parametric model that can be controlled, sampled from, and animated. Our modeling efforts focus on learning human shape (and how it varies with pose) and human movement. Starting with shape, we observe that existing 3D body models like SMPL are based on a fixed 3D mesh topology. While this is ideal for some problems, it lacks the ability to express complex clothing and hair. Realistic human avatars will need a richer and more complex representation. Extending meshes to do this is challenging so we have been exploring new methods based on implicit surfaces and point clouds.
SNARF: Differentiable Forward Skinning for Animating Non-Rigid Neural Implicit Shapes
Chen, X., Zheng, Y., Black, M. J., Hilliges, O., Geiger, A.
https://xuchen-ethz.github.io/snarf/
Neural implicit surface methods represent 3D shape in a continuous and resolution-independent manner using a neural network. This network, for example, represents either the occupancy or the signed distance to the body surface. Given any point in 3D space, the function (ie network) says whether the point is inside or outside the shape or returns the signed distance to the surface. The actual surface is then implicitly defined as the zero level set of the function field. Since neural networks are very flexible, they can learn the complex geometry of people in clothing. This is great because it gives us a way to learn a shape model of clothed people from captured data without being tied to the SMPL mesh.
Applying this idea to articulated structures like the human body, however, is non-trivial. Existing approaches learn a backwards warp field that maps deformed (posed) points to canonical points. However, this is problematic since the backward warp field is pose dependent and thus requires large amounts of data to learn. To address this, SNARF, combines the advantages of linear blend skinning (LBS) for polygonal meshes with those of neural implicit surfaces by learning a forward deformation field without direct supervision. This deformation field is defined in canonical, pose-independent, space, enabling generalization to unseen poses. Learning the deformation field from posed meshes alone is challenging since the correspondences of deformed points are defined implicitly and may not be unique under changes of topology. We propose a forward skinning model that finds all canonical correspondences of any deformed point using iterative root finding. We derive analytical gradients via implicit differentiation, enabling end-to-end training from 3D meshes with bone transformations.
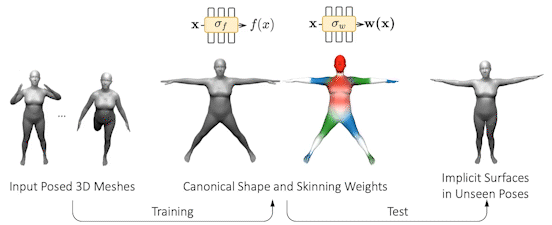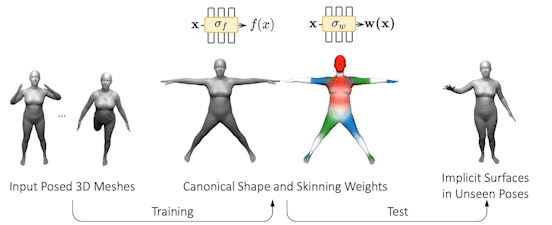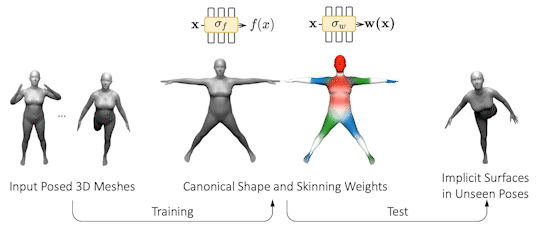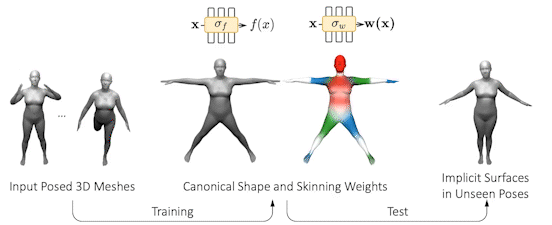
Compared to state-of-the-art neural implicit representations, SNARF generalizes better to unseen poses while preserving accuracy. We demonstrate our method in challenging scenarios on (clothed) 3D humans in diverse and unseen poses.
The Power of Points for Modeling Humans in Clothing
Ma, Q., Yang, J., Tang, S., Black, M. J.
https://qianlim.github.io/POP.html
We think that implicit surfaces are exciting but they have some limitations today. Because they are new, they don't plug and play with any existing graphics technology, which is heavily invested in 3D meshes. For example, you can't use implicit virtual humans in game engines today. To use them, you have to first extract a mesh from the implicit surface, e.g. using marching cubes. We think the "final" model of the 3D body has not yet been discovered and so we are keeping our options open by exploring alternatives.
For example, a very old and simple representation proves particularly powerful -- 3D point clouds. Like implicit surfaces, a point cloud has no fixed topology and the resolution can be arbitrary if you are willing to have lots of points. Such models are very lightweight and easy to render and are much more compatible with existing tools. But there is one problem: they are inherently sparse and the surface is not explicit. The 3D surface that goes through the points is implicit. This is actually quite similar to implicit surfaces and can be learned using a neural network.

There has been a lot of recent work on using point clouds to learn representations of 3D shapes like those in ShapeNet. There are now many deep learning methods that can learn 3D shapes using point clouds, but there has been less work on using them to model articulated and non-rigid objects. To address this, we created a new point-based human model called PoP for the "Power of Points".
PoP is a neural network that is trained with a novel local clothing geometric feature that captures the shape of different outfits. The network is trained from 3D point clouds of many types of clothing, on many bodies, in many poses, and learns to model pose-dependent clothing deformations. The geometry feature can be optimized to fit a previously unseen scan of a person in clothing, enabling us to take a single scan of a person and animate it. This is an important step towards creating virtual humans that can be plugged into the Metaverse.
Action-Conditioned 3D Human Motion Synthesis with Transformer VAE
Petrovich, M., Black, M. J., Varol, G.
https://imagine.enpc.fr/~petrovim/actor/
To create virtual humans we need to ground their movement in language. That is, we need to relate how people move to why they move. What are their goals that drive their behavior? A lot of the prior work on human motion synthesis has focused on time series prediction; i.e., given a sequence of human motion, produce more of it. While interesting, this doesn't get at the core of what we need. We need to give an agent a goal or an action and then have them perform this. Such a performance should be variable in length as well as in how it is executed. For example, if I say "wave goodbye", an avatar might do this with the right or left hand. Natural variability is key to realism.
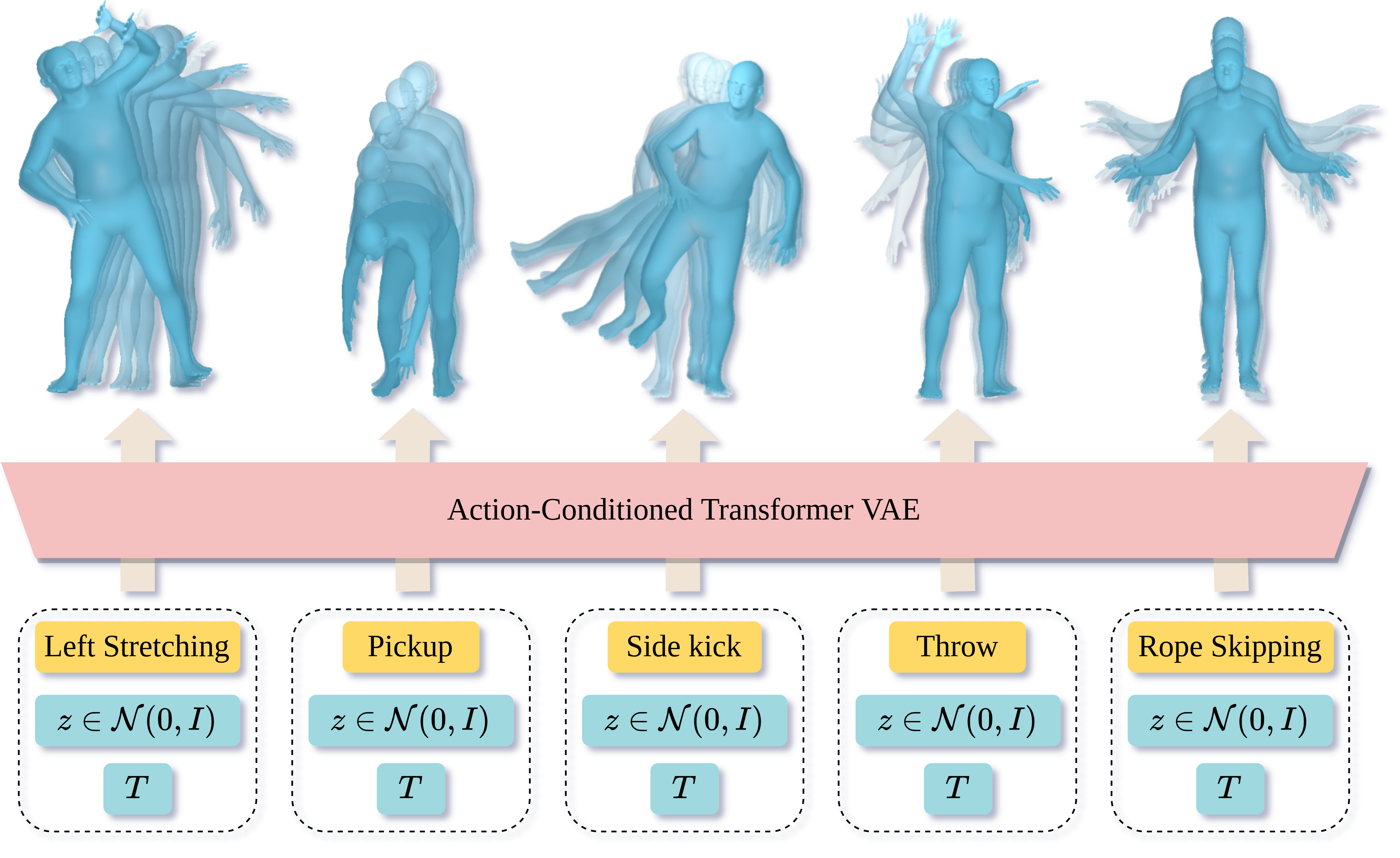
To address this problem we train ACTOR, which is able to generate realistic and diverse human motion sequences of varying length, conditioned on an action label. In contrast to methods that complete, or extend, motion sequences, this task does not require an initial pose or sequence. ACTOR learns an action-aware latent representation of human motions using a generative variational autoencoder (VAE). By sampling from this latent space and querying a certain duration through a series of positional encodings, we synthesize variable-length motion sequences conditioned on an action. Specifically, we design a transformer-based architecture that encodes and decodes a sequence of parametric SMPL human body models estimated from action recognition datasets. We evaluate our approach on the NTU RGB+D, HumanAct12 and UESTC datasets and show improvements over the state of the art in terms of diversity and realism.
Synthesis
How do we know if we've captured the right data and that our models are "good"? Our hypothesis is that, if we can generate realistic human behaviors, then we have done our job. Note that we are a long way from creating truly realistic virtual humans that behave like people. In fact, this is an "AI complete" problem that requires agents with a "theory of mind". While a full solution is still a dream, we can make concrete progress that is useful in the short term.
Stochastic Scene-Aware Motion Prediction
Hassan, M., Ceylan, D., Villegas, R., Saito, J., Yang, J., Zhou, Y., Black, M.
https://samp.is.tue.mpg.de/
In a wonderful collaboration with colleagues at Adobe, we have started to put everything together in a system called SAMP. SAMP uses everything we know to create a virtual human that can plan its actions in a novel scene and move through the scene and interact with objects to achieve a goal, while capturing the natural variability present in human behavior. SAMP builds on our motion capture tools and our prior work on capturing human scene interaction (PROX) as well as recent work on putting static humans into 3D scenes (PSI, PLACE, and POSA).

SAMP stands for Scene-Aware Motion Prediction and is a data-driven stochastic motion synthesis method that models different styles of performing a given action with a target object. SAMP generalizes to target objects of varying geometry, while enabling the character to navigate in cluttered scenes. To train SAMP, we collected mocap data covering various sitting, lying down, walking, and running styles and fit SMPL-X bodies to it using MoSh++. We then augment this data by varying the size and shape of the objects and then adjust the human pose using inverse kinematics to maintain the body-object contacts.
SAMP includes a MotionNet, GoalNet, and A* path planning algorithm. The GoalNet is trained to understand the affordances of objects. We label training data with information about how a human can interact with it; e.g. they can sit or lie on a sofa in different ways. The network learns to stochastically generate interaction states on novel objects. MotionNet is an autoregressive VAE that takes a goal object, the prior body pose, and a latent code and produces the next body pose. An A* algorithm plans a path from a starting pose to the goal object and generates a sequence of waypoints. SAMP then generates motions between these goal states.
SAMP produces natural looking motions and the character avoids obstacles. If you generate the same motion many times, the character will exhibit natural varaibility. While there is still much to do, SAMP is a step towards putting realistic virtual humans in novel 3D scenes and directing them using only high-level goals.
Learning Realistic Human Reposing using Cyclic Self-Supervision with 3D Shape, Pose, and Appearance Consistency
Sanyal, S., Vorobiov, A., Bolkart, T., Loper, M., Mohler, B., Davis, L., Romero, J., Black, M. J.
https://ps.is.mpg.de/publications/spice-iccv-2021
As we improve our models of body shape and motion, we will hit a new barrier to realism. Creating realistic-looking virtual humans using existing graphics rendering methods is still challenging and requires experienced artists. In the same way we are replacing capture with neural networks like SOMA and 3D shape models with neural networks like SNARF or PoP, we can replace the classic graphics rendering pipeline with a neural network. SPICE takes a step in this direction by taking in a single image of a person and then reposing or animating them realistically. By starting with an image and then changing it, we maintain realism. But, even though we are generating pixels, our 3D body models play a critical role.
Synthesizing images of a person in novel poses from a single image is a highly ambiguous task. Most existing approaches require paired training images; i.e. images of the same person with the same clothing in different poses. However, obtaining sufficiently large datasets with paired data is challenging and costly. Previous methods that forego paired supervision lack realism. SPICE (Self-supervised Person Image CrEation) is a self-supervised method that can compete with supervised ones.

Each triplet consists of the source image (left), a reference image in target pose (middle) and the generated image in the target pose (right)
The key insight enabling self-supervision is to exploit 3D information about the human body in several ways. First, the 3D body shape must remain unchanged when reposing. Second, representing body pose in 3D enables reasoning about self occlusions. Third, 3D body parts that are visible before and after reposing, should have similar appearance features. Once trained, SPICE takes an image of a person and generates a new image of that person in a new target pose. SPICE achieves state-of-the-art performance on the DeepFashion dataset, improving the FID score from 29.9 to 7.8 compared with previous unsupervised methods, and with performance similar to the state-of-the-art supervised method (6.4). SPICE also generates temporally coherent videos given an input image and a sequence of poses, despite being trained on static images only.
Summary
What's next? We will continue to improve our capture, modeling and synthesis methods by building on what we have done for ICCV. A key theme running through all our work is
Build what you need and use what you build.
In industry terms, we "eat our own dogfood." Everything you've seen here builds on things we've done before and you can expect future work to build on our ICCV work.
Despite the progress in the field, the capture problem is not yet solved for in-the-wild videos. In particular, we are focused on extracting expressive bodies with faces and hands (see DECA at SIGGRAPH 2021 and PIXIE at 3DV 2021). We are also working with our BABEL dataset to generate more complex human movements that are grounded in action labels. We are developing new implicit shape representations that are richer, more realistic, and easier to learn. In fact, our approach of "capture-model-systhesize" is a virtuous cycle in which synthesized humans can be used to train better capture methods (see AGORA).
The Perceiving Systems Department is a leading Computer Vision group in Germany.
We are part of the Max Planck Institute for Intelligent Systems in Tübingen — the heart of Cyber Valley.
We use Machine Learning to train computers to recover human behavior in fine detail, including face and hand movement. We also recover the 3D structure of the world, its motion, and the objects in it to understand how humans interact with 3D scenes.
By capturing human motion, and modeling behavior, we contibute realistic avatars to Computer Graphics.
To have an impact beyond academia we develop applications in medicine and psychology, spin off companies, and license technology. We make most of our code and data available to the research community.