From cartoons to science: The Sintel dataset at 10 years
The Koenderink Prize at ECCV 2022.
25 October 2022 10 minute read
The Sintel optical flow dataset appeared at ECCV 2012 and at ECCV 2022 it was awarded the Koenderink Prize for work that has stood the test of time. What makes a paper stand the test of time? What makes a good dataset? What made Sintel special?

If you've ever made a dataset for the computer vision community, you know how much work it is. It's also stressful. You put a huge amount of work into it, launch it into the world, and then you wait. Will people use it? Was it worth the effort? Will it advance the field? This is the story of one dataset that caught on. It caught on well enough for the paper describing it to win the Koenderink prize at ECCV 2022. I'll give you a little history and try to explain why I think Sintel (http://sintel.is.tue.mpg.de/) has stood the test of time.
Optical Flow
Optical flow is the 2D motion of image structure between frames in a video sequence. It's related to the 2D motion of the 3D world projected into frames of a video sequence. As such it captures valuable information about the 3D world, the motion of cameras, the boundaries of objects, and the correspondence of structures over time.
Unlike depth, however, there are no sensors that capture or measure optical flow directly. There is no "optical flow camera" that magically gives us the ground truth 2D motion in a video. This lack of ground truth means that we have to work hard to train and to evaluate optical flow. Today there are self-supervised methods that learn to compute flow well but if you want to supervise and evaluate flow algorithms you need synthetic data.
Synthetic Data: Early days
One of the earliest sequences used in evaluating optical flow was the Yosemite sequence. The Yosemite data was originally generated by Lynn Quam at SRI and David Heeger was the first to use it for optical flow experimentation. The sequence was generated by taking an aerial image of Yosemite valley and texture mapping it onto a depth map of the valley. The synthetic sequence was generated by flying through the valley.

For years the field used this one sequence to evaluate methods, effectively fine-tuning to one sequence. There were other early efforts that used very simple synthetic sequences but these bore no resemblance to the real world. And none of the early work provided enough data to apply machine learning to the problem.
Synthetic Data: The Hunt
For years I was on the hunt for realistic graphics data that could be used to render videos with ground truth flow. I wanted to get my hands on the data used to create Spiderman. I talked with numerous special-effects houses and film studios. None of the data was available. Then I started working with JP Lewis who had developed procedural animation tools to render varied sequences. We used his technique to generate the synthetic sequences for the Middlebury Optical Flow Dataset but they did not really match the complexity of real scenes.
Synthetic Data: The Open Source Movie Project
Then one day a clever undergraduate student at Brown named Dan Butler told me about Sintel, which was an open-source movie made in Blender (https://durian.blender.org/). Sintel open sourced all the computer graphics (CG) elements so that anyone could render the movie in Blender. Dan did some quick tests to show that he could render out the optical flow field. Bingo! This looked like it might work.

In August of 2011, I wrote to Ton Roosendaal, who led the open-source Blender project and I pitched the idea that we would use Sintel to create an optical flow dataset for the research community. Ton loved the idea that the movie could be used for science and that Sintel could support a whole new community. It was a prefect use that showed the value of open-source movies.
From a Movie to Data
The whole thing sounded easy. We would just take the movie and use the known 3D motion of everything in the scene to project out the 2D flow. In fact, one of the standard rendering passes generates the 2D flow, which is used to create motion blur. Unfortunately, the CG assets and the rendering process were designed to make compelling movies and not to generate precise data for science. What we wanted was a physically correct world with ground truth motion but what Blender produces is something that looks pretty yet deviates from the truth.
Enter Jonas Wulff, who was a new PhD student in my group at Max Planck. Jonas dove into the guts of Blender and found that the optical flow it rendered was not correct. It was fine for generating motion blur but not physically accurate because it was done by interpolating motions of triangles in 2D, not 3D. He fixed the rendering process to produce the right flow and then addressed many other issues with how Blender renders scenes.
There were so many considerations and modifications that we wrote an entire paper about this, which is like a companion to the original paper.
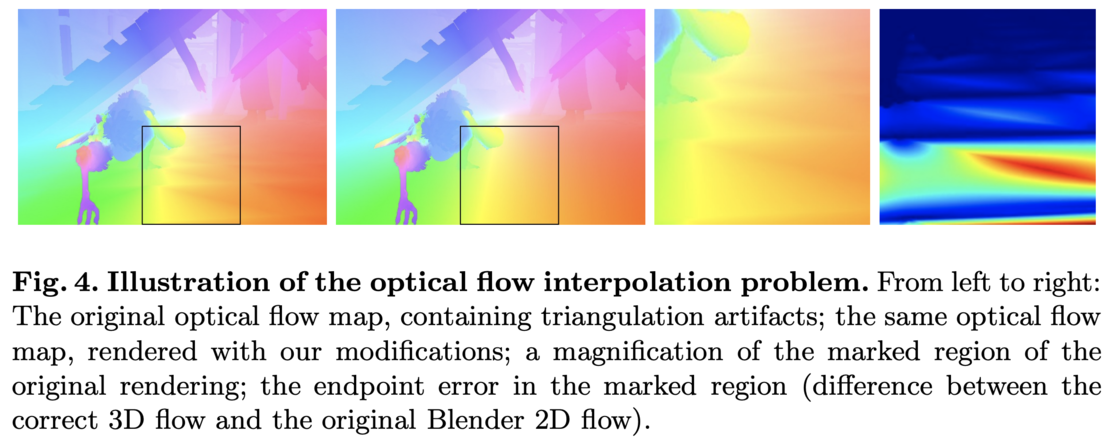
Hard Decisions
I tell anyone who plans to make a dataset to "pick your battles." A dataset can only do so much. It should move the field forward in one important direction. If you try to do too much, it may not be adopted. For example, the original Sintel movie contains transparency and reflections. At the time (and still today) the community had no defined standard for how to represent these as 2D flow. Should one ignore reflections? Or should we allow multiple optical flow vectors at a single pixel? We decided that this was not the key problem facing the field, so we disabled all transparency and reflections. Sintel's hair was rendered as a particle system to make it appear partially transparent. This caused problems so we simplified Sintel's hair and represented it as simple geometry. The version of the Sintel movie that the Computer Vision community uses reflects a myriad of decisions that make it different from the original movie.
So, what did we want the community to focus on? At the time almost all optical flow algorithms processed only pairs of frames. The images were typically small and the motions were also generally small. So, our main goals were to push people to process long sequences with large motions. Initially we had complaints from people who found the data too much to process. This was exactly what we wanted -- to force the community to stretch.
Getting Scientific
Today the idea of using synthetic data to train and test methods is well accepted. There are even many companies like Datagen that make their living from doing exactly this. But in 2012, the use of synthetic data was not widely accepted. In fact, it was viewed with suspicion. Previous synthetic datasets were not realistic and the performance of methods on these datasets did not match performance in real video; i.e., people worried about the domain gap.
Even worse, Sintel is a cartoon. How could it be realistic enough to stand in for the real world? We knew we had to tackle this head on. Enter Garrett Stanley, a professor at Georgia Tech. Garrett and I were excited about using Sintel to generate stimuli for neuroscience experiments and started wondering about how "ecologically" relevant Sintel was. So we started looking at the image statistics of Sintel and natural movies that were roughly matched for content -- we called these movies Lookalikes (a name inspired by Ted Adelson).

We found the distributions were quite similar. But we really wanted to know if the motions were similar. Of course, we couldn't directly make this comparison because we didn't have the ground truth for the Lookalikes. So, what we did was look at computed flow on different datasets, Middlebury, Lookalikes, and Sintel. Computed flow statistics on the Lookalikes and Sintel were very similar.
Garrett visited Max Planck and put a huge amount of effort into this analysis, but it was worth it because it showed that the dataset was what we called "naturalistic" and much closer to the real world then Middlebury.
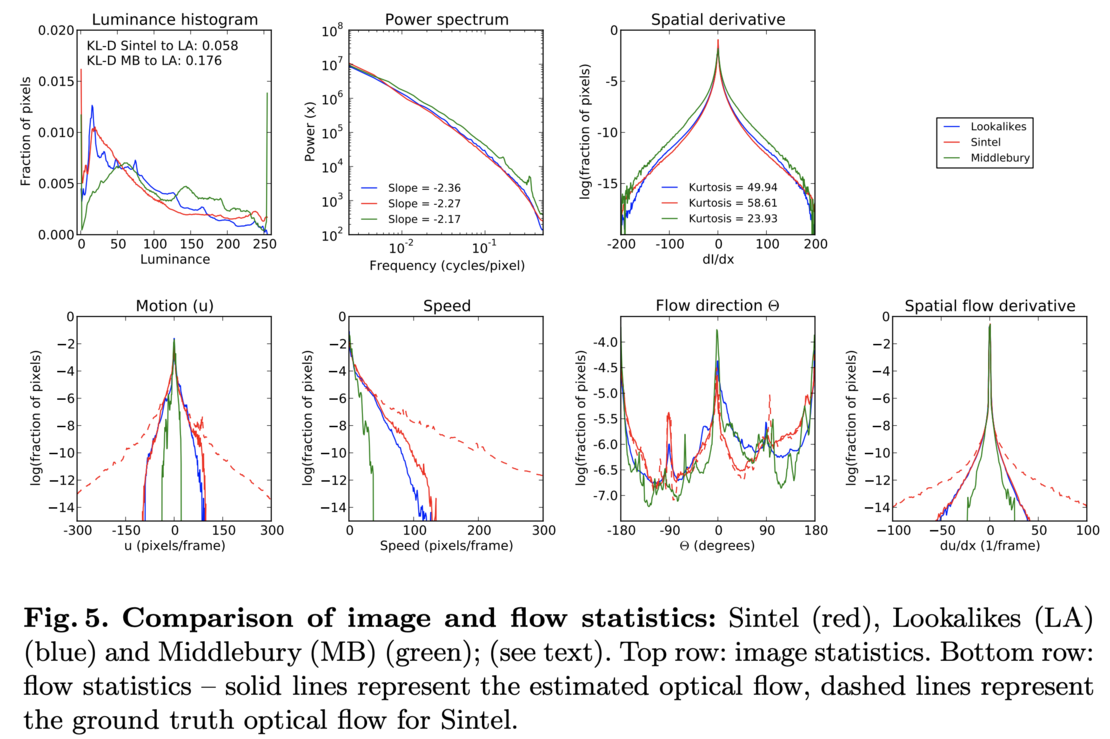
Making of a Benchmark
Dataset adoption is one part science and two parts psychology. People love to compete and be "best" on a dataset. So, the obvious thing is that you need an evaluation server where people can upload results and see where their method ranks. But there are some not-so-obvious issues. For example, you need to decide how to rank people. If you make an evaluation too complex and have lots of different metrics, people will not know which to focus on. You need to pick one thing by which to rank all methods by default.
With Sintel we chose overall 2D endpoint error (EPE) as the main ranking. But we also provided several other metrics that we thought were important to move the community forward. We broke out "matched" pixels that appeared in two consecutive frames and "unmatched" ones that were visible in only one frame (i.e., occlusions or disocclusions). The unmatched ones were where existing methods failed and where the community has made major strides. We also evaluated error by distance from an occlusion boundary and by speed. Still today, the faster the motion or the closer the pixel is to an occlusion boundary, the higher the error.
Another key to a dataset is to provide interesting baselines. If your baseline method is too good, then your dataset isn't hard enough and nobody is going to want to compete with you. Make sure that there is room for improvement.
As I write this, there are 375 methods publicly ranked on the evaluation server and the results are continuing to improve 10 years later
A Little Secret: Make it Pretty
There is another little secret to Sintel's success. It's pretty. The images are fun and colorful. Adding Sintel results to your paper makes it look nice. How often do you get to put images dragons in your papers? I think that this was no small factor in people adopting it, at least in the beginning. If you have never watched the full movie, I highly recommend it.

Preventing Cheating
Any good dataset should withhold the ground truth of the test set and we did this with Sintel. But one of our biggest concerns in releasing Sintel was that people could cheat by downloading the movie and generating the withheld test data themselves. To address this, we built in checks. For example, we modified some of the original sequences in ways that we did not reveal. If a method got much higher errors on the modified frames than the unmodified ones, we would suspect cheating. Fortunately, we haven't detected anyone cheating by using the ground truth.
Learning Optical Flow
When we made Sintel, our idea was to support machine learning methods for optical flow estimation. The problem was, there were few such methods. Deep learning had yet to assert itself and there had never been enough data to effectively learn optical flow (with some execptions like our work at ECCV 2008). As we hoped, Sintel opened up the doors for machine learning methods. What we didn't realize at the time was how much data such methods would need. Sintel was considered huge when it was released but by modern datasets is now tiny.
To address this, later papers from Thomas Brox's team introduced new large-scale synthetic datasets like "Flying Chairs" and "Flying Things" that were less realistic but much larger. Interestingly, size seems more important than realism for training deep networks.
Sintel's Legacy
We certainly didn't invent synthetic data for computer vision. What Sintel did was to show that synthetic data can be realistic enough to be useful. That is, it can be close enough to the physical world that methods trained on the data generalize to real scenes. It also showed that the performance of algorithms on synthetic data predicts performance on real data. The rise of deep learning drastically increased the demand for training data and Sintel showed that synthetic data could be part of the solution.
I'm delighted that Sintel has been awarded the Koenderink Prize for work that has stood the test of time. It was a great team effort to create the dataset, but it's the vision community that brought it to life by using it. Thanks to all the researchers who have used Sintel over the years. I hope you've enjoyed it!
All the Information:
Website: http://sintel.is.tue.mpg.de/ PDF: http://files.is.tue.mpg.de/black/papers/ButlerECCV2012-corrected.pdf YouTube: https://www.youtube.com/watch?v=ZmiBI4tPk_o Reference: @inproceedings{Butler:ECCV:2012, title = {A naturalistic open source movie for optical flow evaluation}, author = {Butler, D. J. and Wulff, J. and Stanley, G. B. and Black, M. J.}, booktitle = {European Conf. on Computer Vision (ECCV)}, pages = {611--625}, series = {Part IV, LNCS 7577}, editors = {{A. Fitzgibbon et al. (Eds.)}}, publisher = {Springer-Verlag}, month = oct, year = {2012}, month_numeric = {10} }The Perceiving Systems Department is a leading Computer Vision group in Germany.
We are part of the Max Planck Institute for Intelligent Systems in Tübingen — the heart of Cyber Valley.
We use Machine Learning to train computers to recover human behavior in fine detail, including face and hand movement. We also recover the 3D structure of the world, its motion, and the objects in it to understand how humans interact with 3D scenes.
By capturing human motion, and modeling behavior, we contibute realistic avatars to Computer Graphics.
To have an impact beyond academia we develop applications in medicine and psychology, spin off companies, and license technology. We make most of our code and data available to the research community.